
资讯
你的位置:2024欧洲杯官网- 欢迎您& > 资讯 >梦晨 发自 凹非寺
量子位 | 公众号 QbitAI视觉自回首模子的Scaling,通常不像在话语模子里那样灵验。
谷歌&MIT何恺明团队联手,有望冲突这一时势,为自回首文生图模子的膨胀指出一个主义:
基于同一token的模子比芜杂token模子在视觉质地上更好。飞速法则生成与光栅法则比拟在GenEval测试上得分赫然更好。
受到这些发现启发,团队磨练了Fluid,一个基于同一标志的飞速法则自回首模子。
膨胀至百亿参数的Fluid在MS-COCO 30K上zero-shot条目下收尾了6.16的FID分数,并在GenEval基准测试中赢得了0.69的举座得分。
团队但愿这些发现和成果省略饱读动异日进一步弥合视觉和话语模子之间的限制差距。
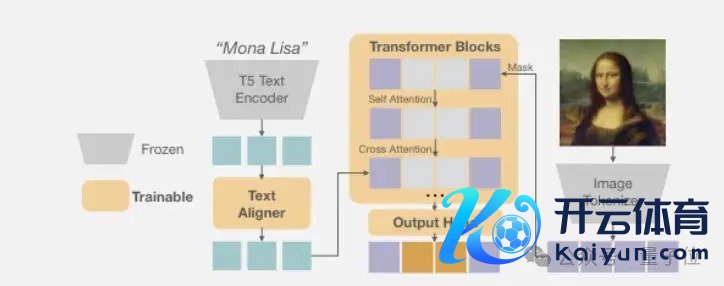
100亿参数自回首文生图模子
回首往日,两个重要遐想身分截止了自回首图像生成模子的性能推崇:
芜杂token。大多数此类模子鉴戒NLP的作念法,先用vector-quantized(VQ)情势将图像芜杂化为一组token,每个token只可取有限的芜杂值。这种量化未免亏蚀大批信息。光栅法则。即按从左到右、从上到下的固定法则生成token。这种神志虽故意于推理加快,但也影响了生成质地。Fluid汲取了团队在本年6月份究诘《Autoregressive Image Generation without Vector Quantization》的念念路,消逝芜杂token,改用同一token。

它鉴戒了扩散模子,用一个微型去噪鸠集近似每个token的同一散播。
具体而言,模子为每个位置的token生成一个向量z算作条目,输入一个微型去噪鸠集。这个去噪鸠集界说了token x在给定z时的条目散播p(x|z)。磨练时,该鸠集与自回首模子长入优化;推理时,从p(x|z)中采样即可得到token。统统这个词进程无需芜杂化,幸免了量化亏蚀。

再来望望生成token的法则。按固定的光栅法则一一生成token,推理时诚然不错用kv缓存加快,但因果关连的截止也影响了生成质地。
Fluid匠心独具,飞速取舍要生成的token,并用访佛BERT双向介怀力的机制捕捉全局信息。
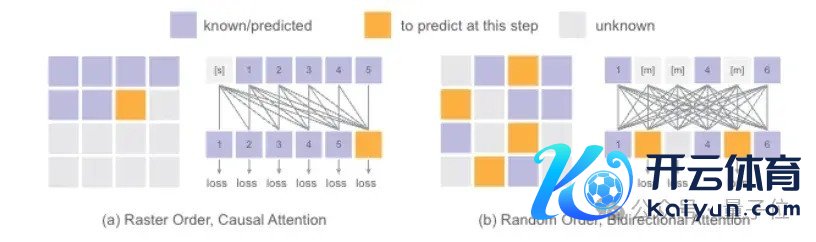
在推理时遴选皆备飞速法则,磨练和推理进程的序列散播更一致;同期还能对每个token进行访佛GPT的temperature采样,进一步擢升了生成千般性。
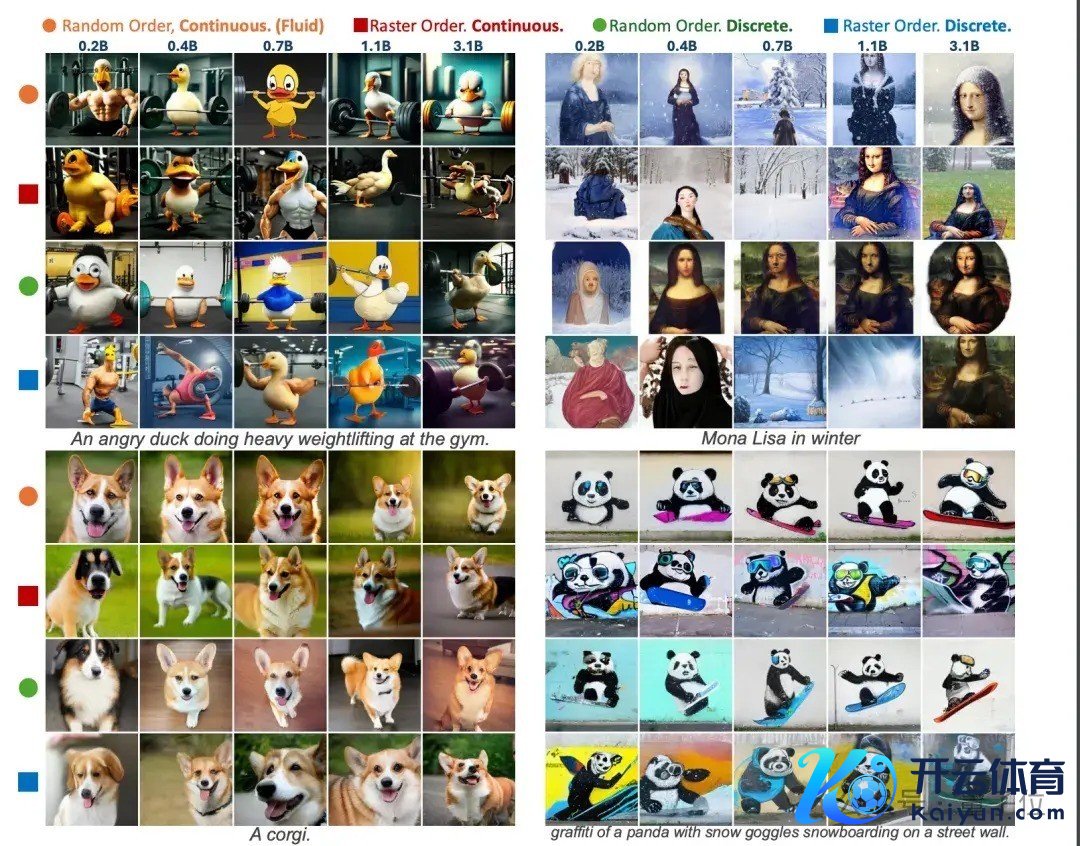
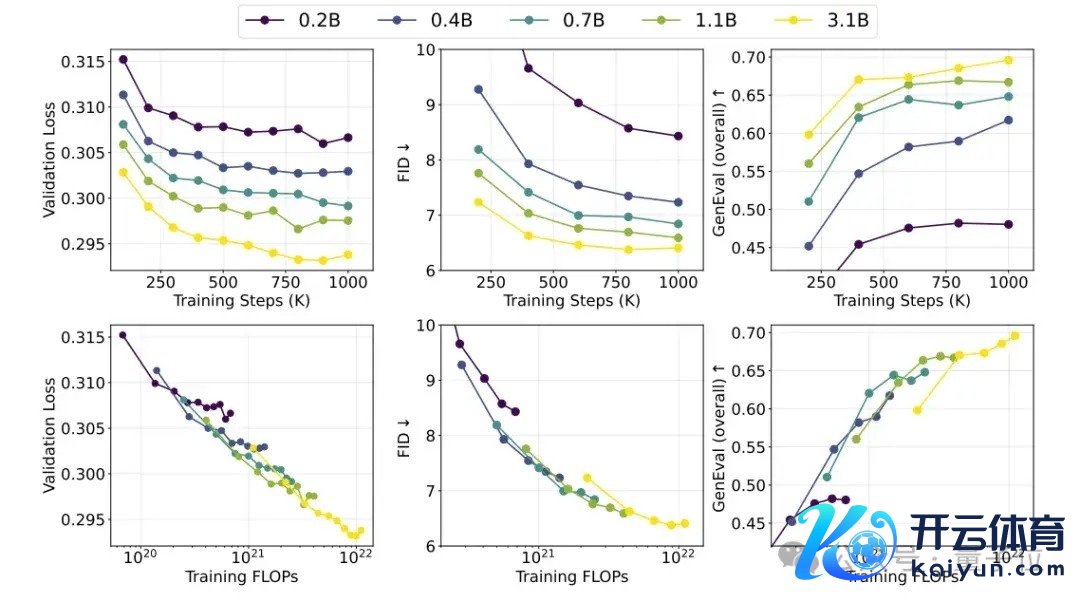
收成于扩散损构怨MAR范式的双重加捏,作家将模子参数目膨胀到跨越100亿,在MS-COCO和GenEval数据集上取得起始成果。
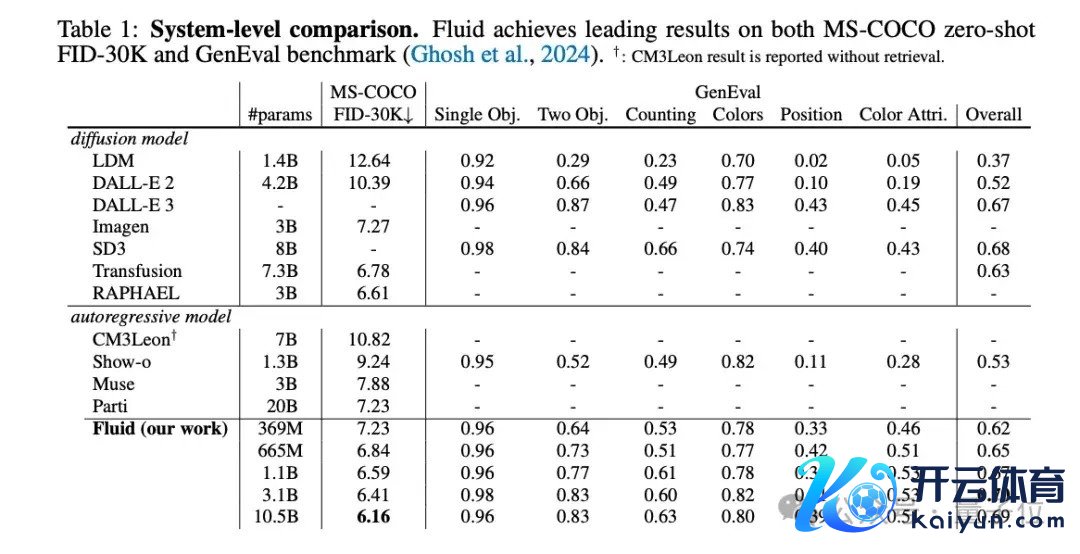
更伏击的是,跟着参数目和磨练轮数的加多,模子在考证亏蚀、FID、GenEval Score等蓄意上推崇出艰深的可膨胀性,为进一步扩大限制提供了表面相沿。这与话语模子的Scaling慷慨超越访佛,标明视觉大模子的后劲尚未被充分挖掘。
更多Fuild模子生成图像精选:

论文地址:
https://arxiv.org/abs/2410.13863— 完 —
量子位 QbitAI · 头条号签约
护理咱们,第一时候获知前沿科技动xtt